第7章 perfmon2—ハードウエアベースの性能監視¶
概要
perfmon2 はプロセッサ性能監視ユニット (PMU) にアクセスするための標準化・汎用 インターフェイスです。各種の PMU モデルやアーキテクチャに対して、可搬性のある アクセス機能を提供します。これによりシステム全体だけでなくスレッド単位での 監視やカウント、およびサンプリングを行なうことができるようになっています。
7.1. 概念¶
perfmon の概要については下記をお読みください。
7.1.1. perfmon2 の構造¶
性能監視とは、 「どのようにアプリケーションやシステムが動作して いるのかについて、情報を収集する行為」 のことを指します。 これらの情報は、動作しているコードから取得することができるほか、 CPU やチップセットなどからも取得することができます。
新しいプロセッサであれば、性能監視ユニット (PMU) と呼ばれるものが搭載 されています。 PMU の設計と機能は CPU ごとに異なる仕様になっていて、 たとえばレジスタの数やカウンタの数、機能数については、 CPU 側の実装に よって異なります。
perfmon インターフェイスは汎用的で柔軟性や拡張性に富んだ設計になって います。そのため、プログラム (スレッド) だけでなくシステム全体のレベル でも監視を行なうことができるようになっていて、いずれの場合でもプロファイル 情報をカウントしたりサンプリングしたりすることができるようになっています。 この統一されたインターフェイスにより、可搬性のあるツールを作成することが できるようになっています。まずは 図7.1「perfmon2 のアーキテクチャ」 で概要をお読みください。
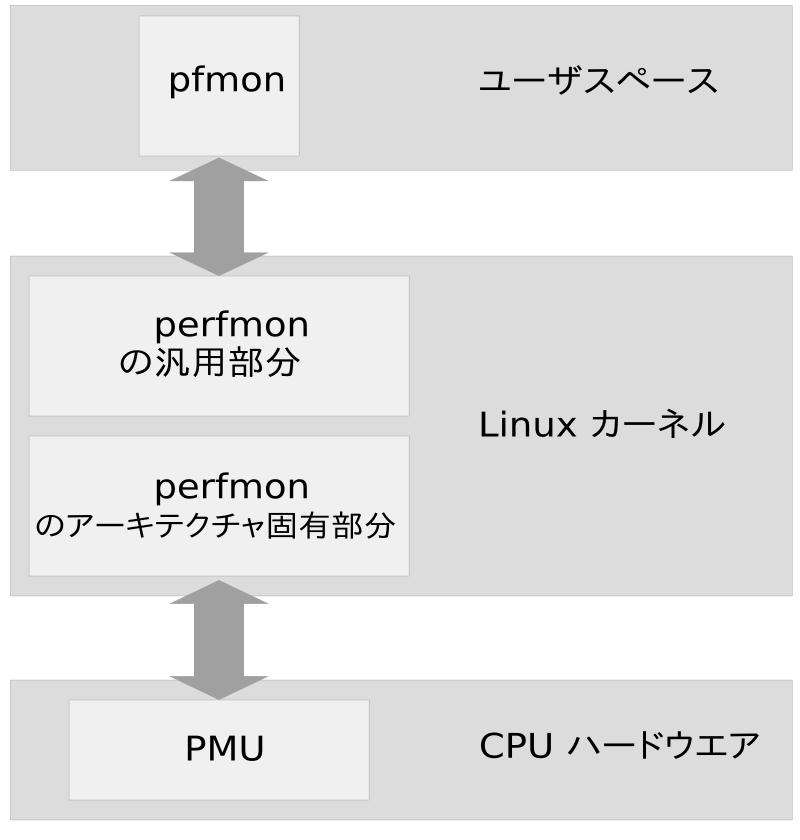
各 PMU は複数のレジスタから構成されています。それぞれ性能モニタ設定 (PMC) と性能モニタデータ (PMD) と呼ばれます。書き込みは PMC 側にだけ 行なうことができますが、読み込みは両方のレジスタで行なうことができます。 これらのレジスタには、設定情報とデータが保存されます。
7.1.2. サンプリングとカウント¶
perfmon2 は 2 種類のモードに対応します。それぞれサンプリングとカウント と呼ばれるものです。
サンプリング とは通常、一定の時間間隔 (時間ベース) や
一定回数のイベント発生間隔 (イベントベース) で処理されるモードです。 perfmon
の場合、時間ベースのサンプリングは、時間で発生するイベント (たとえば
unhalted_reference_cycles など) を利用して間接的に
実現しています。
一方、 カウント はイベントの発生回数を元に処理する モードです。
いずれの情報であっても、それらの情報は サンプル 内に保管されます。このサンプルには、たとえばどのスレッドで発生したものかや、 命令ポインタの情報などが含まれています。
下記の例では CPU_OP_CYCLES イベントの発生回数を数え、
100000 回発生するごとにサンプルを採取します:
pfmon --no-cmd-output -e CPU_OP_CYCLES_ALL /bin/ls 1306604 CPU_OP_CYCLES_ALL
また、下記のコマンドは指定した機能の実行回数と、全体サイクル内での 割合を表示します:
pfmon --no-cmd-output --short-smpl-periods=100000 -e CPU_OP_CYCLES_ALL /bin/ls
# results for [28119:28119<-[28102]] (/bin/ls)
# total samples : 12
# total buffer overflows : 0
#
# event00
# counts %self %cum code addr
1 8.33% 8.33% 0x2000000000007180
1 8.33% 16.67% 0x20000000000195a0
1 8.33% 25.00% 0x2000000000019260
1 8.33% 33.33% 0x2000000000014e60
1 8.33% 41.67% 0x20000000001f38c0
1 8.33% 50.00% 0x20000000001ea481
1 8.33% 58.33% 0x200000000020b260
1 8.33% 66.67% 0x2000000000203490
1 8.33% 75.00% 0x2000000000203360
1 8.33% 83.33% 0x2000000000203440
1 8.33% 91.67% 0x4000000000002690
1 8.33% 100.00% 0x20000000001cfdf17.2. インストール¶
perfmon2 を使用するには、まず下記の要件が満たされていることをご確認ください:
- SUSE Linux Enterprise 11
対応するアーキテクチャは、それぞれ IA64, x86_64 です。
perf(Linux 向けパフォーマンス カウンタ) パッケージの場合は、 x86, PPC64 の各アーキテクチャに対応しています。- SUSE Linux Enterprise 11 SP1
対応するアーキテクチャは IA64 のみです。
SUSE Linux Enterprise11 上の pfmon の場合、それぞれ下記のプロセッサに
対応しています (/usr/share/doc/packages/pfmon/README
からの抜粋):
表7.1 サポート対象のプロセッサ¶
|
型式 |
プロセッサ |
|---|---|
|
Intel IA-64 |
Itanium (Merced), Itanium 2 (McKinley, Madison, Deerfield), Itanium 2 9000/9100 (Montecito, Montvale) など |
|
AMD X86 |
Opteron (K8, fam 10h) |
|
Intel X86 |
Intel P6 (Pentium II, Pentium Pro, Pentium III, Pentium M); Yonah (Core Duo, Core Solo); Netburst (Pentium 4, Xeon); Core (Merom, Penryn, Dunnington) Core 2 または Quad; Atom; Nehalem; architectural perfmon v1, v2, v3 |
お使いのアーキテクチャごとに必要なパッケージが異なります。 必要なパッケージをインストールしてください:
7.3. perfmon の使用¶
perfmon を使用する場合、 pfmon と呼ばれるコマンドライン ツールを利用してすべての情報収集を行ないます。
![[Note]](static/images/note.png) | perfmon と OProfile セッションの同時使用について |
|---|---|
x86 アーキテクチャの場合、 perfmon のセッションと OProfile のセッションを 同時に起動することはできません。一方をお使いの場合は、他方を停止させて ください。 | |
7.3.1. イベント情報の取得¶
利用可能なイベントの一覧を取得するには、 pfmon
コマンドに -l を付与して実行してください。なお、この
一覧はホスト側の PMU によってそれぞれ異なることに注意してください:
pfmon -l ALAT_CAPACITY_MISS_ALL ALAT_CAPACITY_MISS_FP ALAT_CAPACITY_MISS_INT BACK_END_BUBBLE_ALL BACK_END_BUBBLE_FE BACK_END_BUBBLE_L1D_FPU_RSE ... CPU_CPL_CHANGES_ALL CPU_CPL_CHANGES_LVL0 CPU_CPL_CHANGES_LVL1 CPU_CPL_CHANGES_LVL2 CPU_CPL_CHANGES_LVL3 CPU_OP_CYCLES_ALL CPU_OP_CYCLES_QUAL CPU_OP_CYCLES_HALTED DATA_DEBUG_REGISTER_FAULT DATA_DEBUG_REGISTER_MATCHES DATA_EAR_ALAT ...
各項目について説明を読みたい場合は、 -i に続けてイベント名
を指定します:
pfmon -i CPU_OP_CYCLES_ALL Name : CPU_OP_CYCLES_ALL Code : 0x12 Counters : [ 4 5 6 7 8 9 10 11 12 13 14 15 ] Desc : CPU Operating Cycles -- All CPU cycles counted Umask : 0x0 EAR : None ETB : No MaxIncr : 1 (Threshold 0) Qual : None Type : Causal Set : None
7.3.2. システム全体に対するセッションの有効化¶
--system-wide オプションを使用すると、特定の CPU
(単体または複数) 上で実行されるすべてのプロセスを監視することができます。
この場合も、 root で実行する必要はありません。既定ではユーザレベルが
全イベントに対して有効になっているためです (-u オプション)。
また、同じ CPU を監視しない限り、複数のシステム全体セッションを同時に実行する こともできます。ただし、スレッドごとのセッションとシステム全体のセッションは 同時には実行できません。
下記の例では、 Itanium IA64 Montecito プロセッサを利用して採取した例です。 システム全体のセッションを実行するには、下記の手順を行ないます:
お使いの CPU セットを検出します:
pfmon -v --system-wide ... selected CPUs (2 CPU in set, 2 CPUs online): CPU0 CPU1
セッションに制約を設定します。下記の一覧では、以降の例で使用するオプション について説明を記述しています (詳しくはマニュアルページをお読みください):
-e/--events選択したイベントのみをプロファイルします。一覧を取得するには、 7.3.1項 「イベント情報の取得」 をお読みください。
--cpu-list監視対象のプロセッサ一覧を指定します。このオプションを指定しない場合、 利用可能なすべてのプロセッサを監視します。
-t/--session-timeout監視セッションの実行時間を秒単位で指定します。
プロファイルセッションを開始するには、上記のいずれかの方法をご利用ください。
既定のイベントを使用します:
pfmon --cpu-list=0-2 --system-wide -k -e CPU_OP_CYCLES_ALL,IA64_INST_RETIRED <press ENTER to stop session> CPU0 7670609 CPU_OP_CYCLES_ALL CPU0 4380453 IA64_INST_RETIRED CPU1 7061159 CPU_OP_CYCLES_ALL CPU1 4143020 IA64_INST_RETIRED CPU2 7194110 CPU_OP_CYCLES_ALL CPU2 4168239 IA64_INST_RETIRED
秒単位で実行時間を指定します:
pfmon --cpu-list=0-2 --system-wide --session-timeout=10 -k -e CPU_OP_CYCLES_ALL,IA64_INST_RETIRED <session to end in 10 seconds> CPU0 69263547 CPU_OP_CYCLES_ALL CPU0 38682141 IA64_INST_RETIRED CPU1 87189093 CPU_OP_CYCLES_ALL CPU1 54684852 IA64_INST_RETIRED CPU2 64441287 CPU_OP_CYCLES_ALL CPU2 37883915 IA64_INST_RETIRED
コマンドを実行します。セッションはプログラムを起動することで自動的に 開始され、プログラムが終了すると自動的に停止されます:
pfmon --cpu-list=0-1 --system-wide -u -e CPU_OP_CYCLES_ALL,IA64_INST_RETIRED -- ls -l /dev/null crw-rw-rw- 1 root root 1, 3 27. Mär 03:30 /dev/null CPU0 38925 CPU_OP_CYCLES_ALL CPU0 7510 IA64_INST_RETIRED CPU1 9825 CPU_OP_CYCLES_ALL CPU1 1676 IA64_INST_RETIRED
Enter キーを押すとセッションを停止することができます:
合計値を取得したい場合は、対象となるコマンドの後に
-aggrオプションを指定します:pfmon --cpu-list=0-1 --system-wide -u -e CPU_OP_CYCLES_ALL,IA64_INST_RETIRED --aggr <press ENTER to stop session> 52655 CPU_OP_CYCLES_ALL 53164 IA64_INST_RETIRED
7.3.3. 動作中の処理の監視¶
perfmon は動作中のスレッドを監視することもできます。これは、起動に時間のかかる システムデーモンやプログラムを監視する場合に便利な機能です。この場合は、 まず監視対象のプロセス ID を判断します:
ps ax | grep foo
10027 pts/1 R 2:23 foo
あとは見つかったプロセス ID を、 pfmon コマンドの
--attach-task オプションで指定します:
pfmon --attach-task=10027 3682190 CPU_OP_CYCLES_ALL
7.4. debugfs からの統計情報取得¶
perfmon は、デバッグ用のインターフェイスで公開されている統計情報を 収集することもできます。この方法では、多くが合計値としてのカウントや 間隔として採取されます。
データへのアクセスは、 root で /sys/kernel/debug
以下にマウントされた、デバッグファイルシステムを通じて行ないます。
テータは /sys/kernel/debug/perfmon/ 内に CPU 単位で
存在しています。それぞれの CPU には、 ASCII ファイル形式でアクセス可能な
複数の測定値が含まれています。下記の情報は
/usr/src/linux/Documentation/perfmon2-debugfs.txt
からの抜粋です:
表7.3 /sys/kernel/debug/perfmon/cpu*/ 内にある読み取り専用ファイル¶
|
ファイル |
説明 |
|---|---|
|
|
PMU コンテキスト切り替えの突入回数 |
|
|
PMU コンテキスト切り替え突入ルーチン内で消費された時間 (ナノ秒単位) Average cost of the PMU context switch in = ctxswin_ns / ctxswin_count |
|
|
PMU コンテキスト切り替えの解放回数 |
|
|
PMU コンテキスト切り替え解放ルーチン内で消費された時間 (ナノ秒単位) Average cost of the PMU context switch out = ctxswout_ns / ctxswout_count |
|
|
PMU の割り込みを処理する、サンプル採取書式化ルーチン (一般的にはサンプルを記録するルーチン) の呼び出し回数 |
|
|
PMU サンプル採取書式化ルーチン内で消費された時間 (ナノ秒単位) Average time spent in this routine = fmt_handler_ns / fmt_handler_calls |
|
|
|
|
|
|
|
|
カーネルが受信した PMU 割り込みの回数 |
|
|
perfmon からカーネルが受信した、マスク不可能な割り込み (NMI) の回数 (X86 ハードウエアのみ) |
|
|
perfmon2 PMU 割り込み処理ルーチン内で消費された時間 (ナノ秒単位) Average time to handle one PMU interrupt = ovfl_intr_ns / ovfl_intr_all_count |
|
|
perfmon の割り込み処理ルーチンが処理を行なった PMU 割り込みの回数 |
|
|
コンテキスト切り替えの突入やイベントセットの切り替えなどで再実行 された PMU 割り込みの回数 |
|
|
有効なコンテキスト情報が存在しなかったために捨てられた、 PMU 割り込みの回数 |
|
|
|
|
|
|
|
|
イベントセットの切り替え回数 |
|
|
セット切り替えルーチン内で消費された時間 (ナノ秒単位) Average cost of switching sets = set_switch_ns / set_switch_count |
perfmon の実行前後でこれらの情報を比較するという方法もあります。たとえば 下記のようにしてデータを採取します:
for i in /sys/kernel/debug/perfmon/cpu0/*; do echo "$i:"; cat $i done >> pfmon-before.txt
次に、特定の CPU に限定して性能監視を行ないます:
pfmon --cpu-list=0 ...
再度データを採取します:
for i in /sys/kernel/debug//perfmon/cpu0/*; do echo "$i:"; cat $i done >> pfmon-after.txt
採取した 2 つの値を比較します:
diff -u pfmon-before.txt pfmon-after.txt
7.5. さらなる情報¶
この章では概要のみを説明してきました。より詳しい情報については、それぞれ 下記のリンク先をお読みください:
- http://perfmon2.sourceforge.net/
プロジェクトの Web ページです。
- http://www.iop.org/EJ/article/1742-6596/119/4/042017/jpconf8_119_042017.pdf
PDF 形式での概要説明です。
- 第8章 OProfile—システム全体に対するプロファイラ
その他の性能最適化については、こちらの章をお読みください。